Table of Contents

Last year, I built a feature for this very website — an AI assistant that can answer questions about me, my work, and my blog. The question I had to answer before writing a single line of code was: should I use RAG or fine-tune a model?
I chose RAG. And it was the right call — for that project. But it’s not always the right call.
After building multiple AI-powered products — from internal knowledge bots to content recommendation engines — I’ve learned that the “RAG vs fine-tuning” debate isn’t about which one is better. It’s about which one fits the problem you’re actually solving.
In this post, I’ll break down both approaches from the perspective of someone who’s actually built with both. No theoretical fluff. Real costs, real trade-offs, real code, and a clear decision framework you can use today.
The Core Problem Both Solve
Large Language Models like GPT-4.5, Claude Opus 4.5, and Gemini 3 Pro are incredibly capable. But they share two fundamental limitations:
- Knowledge cutoff — They don’t know what happened after their training date.
- No access to your data — They’ve never seen your company’s documents, your product database, or your internal policies.
Both RAG and fine-tuning are strategies to bridge this gap, but they do it in fundamentally different ways.
Think of it like this:
RAG is like giving someone a library card. They don’t memorise the books — they look things up when asked.
Fine-tuning is like sending someone to medical school. The knowledge becomes part of who they are.
Neither approach is universally better. The right choice depends on your data, your budget, your latency requirements, and how often your information changes.
What Is RAG (Retrieval-Augmented Generation)?
RAG is an architecture pattern where the AI model retrieves relevant information from external sources before generating a response. Instead of relying solely on what it learned during training, the model gets fresh, contextual data injected into every query.
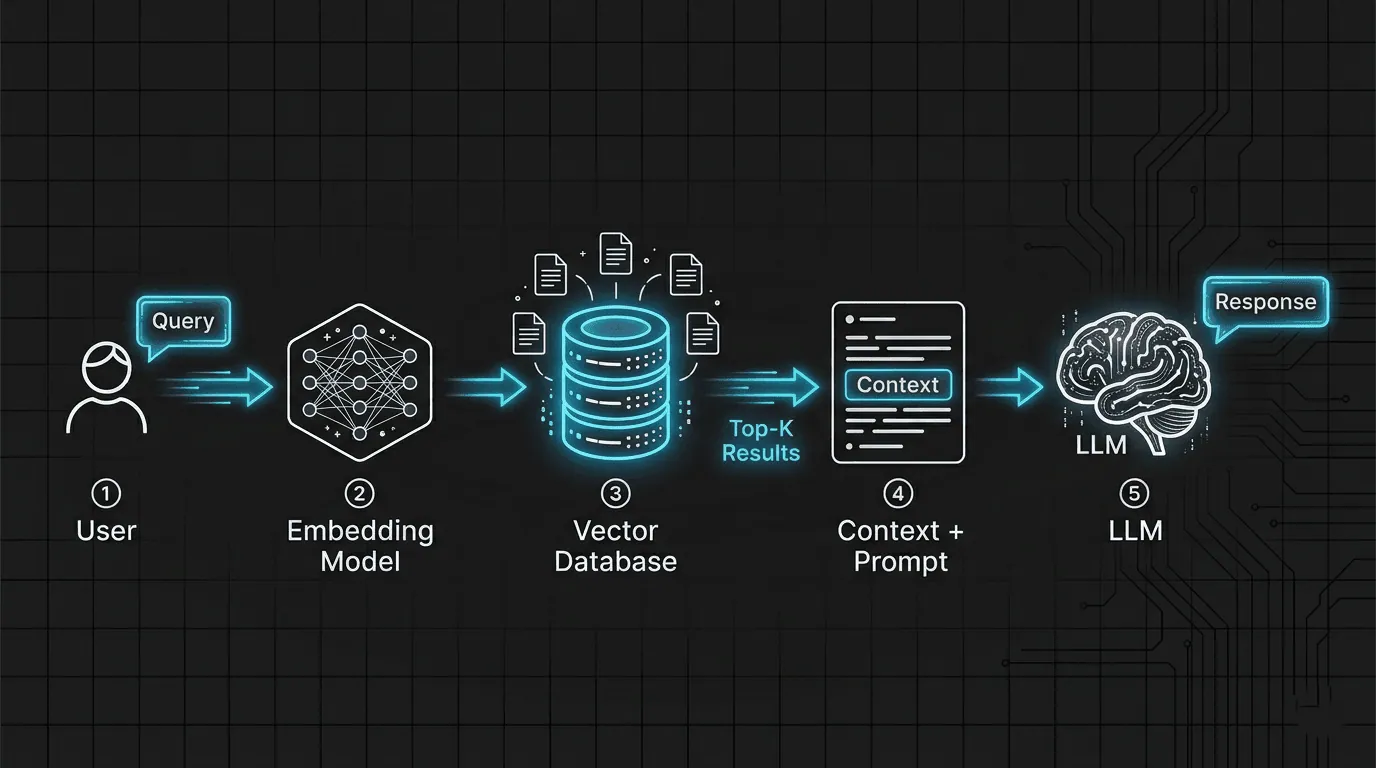
How RAG Works — Step by Step
User Query → Embedding → Vector Search → Retrieve Top-K Documents →
Inject into Prompt → LLM Generates Answer
Here’s the detailed flow:
-
Your documents are pre-processed — Text is split into chunks, converted into vector embeddings, and stored in a vector database (like Pinecone, Weaviate, Qdrant, or even a simple JSON file).
-
User asks a question — The query is converted into an embedding using the same model.
-
Semantic search — The system finds the most relevant document chunks by comparing vector similarity (cosine similarity, dot product, etc.).
-
Context injection — The retrieved chunks are added to the LLM’s prompt as context.
-
Generation — The LLM generates a response grounded in the retrieved information.
A Real RAG Implementation — From My Own Site
I built a RAG-powered AI assistant for xahidex.com. Here’s a simplified version of how I generate embeddings for my knowledge base:
// Generate embeddings for knowledge base documents
import { readFileSync } from 'fs';
import { join } from 'path';
interface EmbeddingEntry {
text: string;
embedding: number[];
source: string;
}
async function generateEmbeddings(
documents: { content: string; source: string }[]
): Promise<EmbeddingEntry[]> {
const entries: EmbeddingEntry[] = [];
for (const doc of documents) {
// Split into manageable chunks (~500 tokens each)
const chunks = splitIntoChunks(doc.content, 500);
for (const chunk of chunks) {
const embedding = await getEmbedding(chunk);
entries.push({
text: chunk,
embedding,
source: doc.source,
});
}
}
return entries;
}
function splitIntoChunks(text: string, maxTokens: number): string[] {
const sentences = text.split(/(?<=[.!?])\s+/);
const chunks: string[] = [];
let current = '';
for (const sentence of sentences) {
if ((current + sentence).length > maxTokens * 4) {
if (current) chunks.push(current.trim());
current = sentence;
} else {
current += ' ' + sentence;
}
}
if (current) chunks.push(current.trim());
return chunks;
}And here’s how the retrieval works at query time:
function cosineSimilarity(a: number[], b: number[]): number {
const dot = a.reduce((sum, val, i) => sum + val * b[i], 0);
const magA = Math.sqrt(a.reduce((sum, val) => sum + val * val, 0));
const magB = Math.sqrt(b.reduce((sum, val) => sum + val * val, 0));
return dot / (magA * magB);
}
async function retrieveContext(
query: string,
embeddings: EmbeddingEntry[],
topK: number = 5
): Promise<string> {
const queryEmbedding = await getEmbedding(query);
const scored = embeddings
.map((entry) => ({
...entry,
score: cosineSimilarity(queryEmbedding, entry.embedding),
}))
.sort((a, b) => b.score - a.score)
.slice(0, topK);
return scored.map((s) => s.text).join('\n\n');
}This is RAG in its simplest form. No vector database, no complex infrastructure — just embeddings stored in a JSON file, cosine similarity for search, and context injected into the prompt. It works surprisingly well for personal sites and small-scale applications.
When RAG Shines
| Scenario | Why RAG Works |
|---|---|
| Data changes frequently | Re-embed new docs, no retraining needed |
| You need source citations | RAG naturally knows where it got the info |
| Company knowledge bases | Internal docs, FAQs, policies — all searchable |
| Real-time information | Plug in live APIs as data sources |
| Budget is limited | No GPU costs for training |
| Regulatory compliance | You control exactly what data the model can access |
RAG Limitations
- Retrieval quality is the bottleneck — If the search returns irrelevant chunks, the answer will be wrong (garbage in, garbage out).
- Context window limits — You can only inject so much context. With very large knowledge bases, you need smart chunking and ranking strategies.
- Latency — The retrieval step adds time. Expect 200-800ms overhead depending on your vector DB and infrastructure.
- Can’t change the model’s behaviour — RAG feeds information, but it can’t change how the model writes, reasons, or formats responses.
What Is Fine-Tuning?
Fine-tuning is the process of further training a pre-trained LLM on your own dataset. Unlike RAG, which works around the model, fine-tuning modifies the model’s weights — embedding new knowledge and behaviours directly into the neural network.
How Fine-Tuning Works
Base Model + Your Training Data → Training Process →
Custom Model (new weights) → Deploy → Inference
- Prepare training data — Typically as instruction-response pairs (JSONL format).
- Choose a base model — GPT-4o-mini, LLaMA 3.3, Mistral, Qwen 2.5, etc.
- Train — The model’s weights are updated using your data. This can take minutes to hours depending on dataset size and model.
- Deploy — Your custom model is now available for inference.
- Evaluate — Test against held-out examples to measure quality.
Fine-Tuning Training Data Example
[
{
"messages": [
{
"role": "system",
"content": "You are an AI assistant for a Dubai-based healthcare clinic. Answer patient queries professionally and accurately."
},
{
"role": "user",
"content": "What are your paediatric vaccination packages?"
},
{
"role": "assistant",
"content": "We offer comprehensive paediatric vaccination packages following the UAE Ministry of Health schedule. Our packages include: 1) Newborn Package (0-12 months) covering BCG, Hepatitis B, DPT, and MMR vaccines. 2) Toddler Package (1-4 years) including boosters and additional immunisations. Please call our clinic to book a consultation with our paediatric team."
}
]
},
{
"messages": [
{
"role": "user",
"content": "Do you accept insurance?"
},
{
"role": "assistant",
"content": "Yes, we accept major insurance providers in the UAE including DHA, Daman, Oman Insurance, AXA, Cigna, MetLife, and Neuron. For a complete list or to verify your specific plan, please contact our reception team."
}
]
}
]Fine-Tuning With OpenAI — Quick Example
# Upload training data
openai api fine_tuning.jobs.create \
-t "file-abc123" \
-m "gpt-4o-mini-2024-07-18"from openai import OpenAI
client = OpenAI()
# Create fine-tuning job
job = client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4o-mini-2024-07-18",
hyperparameters={
"n_epochs": 3,
"learning_rate_multiplier": 1.8,
}
)
# Use your fine-tuned model
response = client.chat.completions.create(
model="ft:gpt-4o-mini-2024-07-18:your-org::abc123",
messages=[
{"role": "user", "content": "What vaccines does a 6-month-old need?"}
]
)When Fine-Tuning Shines
| Scenario | Why Fine-Tuning Works |
|---|---|
| Custom tone/style | Train the model to write like your brand |
| Domain-specific reasoning | Medical, legal, financial — where precision matters |
| Structured output | Consistent JSON, specific formats every time |
| Reducing prompt length | Bake instructions into the model instead of the prompt |
| Classification tasks | Sentiment analysis, intent detection, categorisation |
| Offline/edge deployment | Fine-tuned small models can run locally |
Fine-Tuning Limitations
- Expensive — GPU compute for training isn’t cheap. Even with LoRA/QLoRA, you need decent hardware.
- Data preparation is tedious — You need hundreds to thousands of high-quality examples.
- Stale knowledge — Fine-tuned models can’t update their knowledge without retraining.
- Overfitting risk — Train too much on narrow data and the model loses general ability.
- No source attribution — The model “just knows” things — it can’t tell you where it learned them.
RAG vs Fine-Tuning: The Complete Comparison
Here’s the comparison table I wish I had when I started building AI features:
| Factor | RAG | Fine-Tuning |
|---|---|---|
| What it changes | The input (context) | The model (weights) |
| Knowledge updates | Instant (re-embed new docs) | Requires retraining |
| Setup cost | Low ($0-50/month for most projects) | Medium-High ($50-5,000+ depending on scale) |
| Running cost | Higher per query (retrieval + longer prompts) | Lower per query (shorter prompts, baked-in knowledge) |
| Latency | +200-800ms for retrieval | No additional latency |
| Data needed | Raw documents (any format) | Curated instruction-response pairs (100s-1000s) |
| Hallucination risk | Lower (grounded in retrieved docs) | Higher (can confidently state wrong info) |
| Source attribution | Yes (knows which document it used) | No |
| Custom behaviour | Limited | Full control over tone, format, reasoning |
| Best for | Knowledge-heavy Q&A, search, support | Style, classification, domain reasoning |
| Maintenance | Update documents, re-embed | Re-train periodically |
| Privacy | Data stays in your vector DB | Data used in training (check provider policies) |
The Decision Framework: Which One Should You Use?
After building with both, here’s the decision framework I use for every new AI project:
Choose RAG If:
- ✅ Your data changes frequently (weekly or more)
- ✅ You need citations and source transparency
- ✅ You’re building a Q&A system over documents
- ✅ Budget is tight and you can’t afford training costs
- ✅ You need it working in days, not weeks
- ✅ Compliance requires you to control data access
- ✅ Your knowledge base is large (1,000+ documents)
Choose Fine-Tuning If:
- ✅ You need a specific writing style or tone
- ✅ Your data is stable and doesn’t change often
- ✅ You need consistent structured outputs (JSON, XML, etc.)
- ✅ You’re building a classifier or intent detector
- ✅ Latency is critical (every millisecond matters)
- ✅ You want to reduce token costs at scale
- ✅ The task requires domain-specific reasoning
Choose Both (Hybrid) If:
- ✅ You need custom behavior AND up-to-date knowledge
- ✅ You’re building a production system at scale
- ✅ You want the best possible quality regardless of complexity
The Hybrid Approach: Why Not Both?
Here’s what most blog posts about this topic miss: you can use RAG and fine-tuning together. In fact, for production systems, combining both often gives the best results.
How the Hybrid Works
Fine-Tuned Model (custom behaviour + domain knowledge)
+
RAG Pipeline (fresh, up-to-date context)
=
Best of both worlds
Example: Imagine you’re building an AI assistant for a law firm.
- Fine-tune the model on thousands of legal documents so it understands legal language, citation formats, and reasoning patterns.
- Use RAG to retrieve the specific case laws, statutes, and client documents relevant to each query.
The fine-tuned model knows how to think like a lawyer. RAG gives it the specific facts it needs for this particular case.
A Real-World Hybrid Architecture
// 1. Fine-tuned model handles the reasoning
const model = 'ft:gpt-4o-mini:your-org::legal-assistant-v2';
// 2. RAG retrieves relevant documents
const context = await retrieveContext(userQuery, legalEmbeddings, 8);
// 3. Combine: fine-tuned behaviour + RAG context
const response = await openai.chat.completions.create({
model,
messages: [
{
role: 'system',
content: `You are a legal research assistant. Use the following
case documents to support your analysis. Always cite specific
sections and precedents.\n\nRelevant Documents:\n${context}`,
},
{ role: 'user', content: userQuery },
],
});This is where the magic happens. The fine-tuned model already knows legal terminology and formats, so it needs fewer instructions in the prompt. RAG provides the specific, up-to-date case information. Together, they produce responses that neither could achieve alone.
Real Cost Breakdown (2026 Pricing)
Let’s talk real numbers. This is something most articles gloss over.
RAG Costs
| Component | Service | Cost |
|---|---|---|
| Embeddings (generation) | OpenAI text-embedding-3-small | $0.02 per 1M tokens |
| Vector database | Pinecone (starter) | Free tier / $70/month |
| Vector database | Qdrant Cloud | Free tier / $25/month |
| Vector database | Self-hosted (JSON/SQLite) | $0 |
| LLM queries | GPT-4o-mini | $0.15 per 1M input tokens |
| LLM queries | Claude 3.5 Haiku | $0.25 per 1M input tokens |
Typical monthly cost for a small RAG app: $5-50/month
For my personal site’s AI assistant, I spend approximately $3/month — embeddings stored in a JSON file (free), and I pay only for the LLM inference per query.
Fine-Tuning Costs
| Component | Service | Cost |
|---|---|---|
| Training | OpenAI GPT-4o-mini | $3.00 per 1M training tokens |
| Training | OpenAI GPT-4o | $25.00 per 1M training tokens |
| Training | Self-hosted (LLaMA 3.3) | ~$2-10/hour GPU rental |
| Inference | Fine-tuned GPT-4o-mini | $0.30 per 1M input tokens (2x base) |
| Data preparation | Manual curation | Your time (most expensive part) |
Typical cost for a fine-tuning project: $50-500+ one-time, then ongoing inference costs.
Cost Comparison for 10,000 Queries/Month
| Approach | Monthly Cost Estimate |
|---|---|
| RAG with GPT-4o-mini | ~$8-15 |
| Fine-tuned GPT-4o-mini | ~$5-10 (lower per query, no retrieval) |
| Hybrid (both) | ~$12-20 |
| Self-hosted RAG (Ollama + local) | ~$0 (just electricity) |
The takeaway: RAG is cheaper to start, fine-tuning is cheaper at scale. For most indie projects and small businesses, RAG is the pragmatic choice.
Beyond Basic RAG: Advanced Patterns in 2026
The RAG landscape has evolved significantly. Here are the patterns I’m paying attention to:
1. GraphRAG
Traditional RAG treats documents as isolated chunks. GraphRAG builds a knowledge graph from your documents, understanding relationships between entities. When you ask a question, it traverses the graph to find connected information — not just similar text.
Traditional RAG: "Find chunks that mention X"
GraphRAG: "Find chunks about X, then follow relationships to Y and Z"
This is particularly powerful for complex domains where information is interconnected — like medical records, legal cases, or technical documentation.
2. Agentic RAG
Instead of a single retrieval step, agentic RAG uses AI agents that can:
- Decide which data sources to query
- Reformulate queries if initial results are poor
- Chain multiple retrievals together
- Validate retrieved information before using it
Think of it as RAG with a brain — the system doesn’t just blindly retrieve and inject, it strategically hunts for the right information.
3. MCP-Based RAG
With the rise of Model Context Protocol (MCP), RAG is getting a standardised interface. Instead of building custom retrieval pipelines, you can expose your knowledge base as an MCP resource. Any MCP-compatible AI (Claude, GPT, Gemini) can then access it through a standard protocol.
I wrote about MCP in detail — it’s changing how we think about connecting AI to data.
4. Late-Interaction Retrieval (ColBERT v2+)
Instead of compressing an entire document chunk into a single embedding vector, late-interaction models keep token-level embeddings. This allows for much more precise matching at query time. It’s computationally heavier but significantly more accurate for technical or nuanced queries.
Beyond Basic Fine-Tuning: Modern Techniques
Fine-tuning has also evolved well beyond “train the whole model on your data”:
1. LoRA (Low-Rank Adaptation)
Instead of updating all model parameters, LoRA adds small trainable matrices to specific layers. This reduces training cost by 10-100x while maintaining most of the quality. It’s the standard for fine-tuning open-source models in 2026.
2. QLoRA (Quantized LoRA)
Combines quantization (reducing model precision to 4-bit) with LoRA. This means you can fine-tune a 70B parameter model on a single consumer GPU. A few years ago, this would have required a cluster.
3. DPO (Direct Preference Optimisation)
Instead of training on “correct” answers, DPO trains on human preferences — “response A is better than response B.” This is incredibly effective for aligning model behaviour with what humans actually want.
4. Synthetic Data Fine-Tuning
Use a stronger model (like GPT-4.5 or Claude Opus) to generate training data for a smaller model. This is becoming the standard approach for building cost-effective, domain-specific models. You get 80-90% of the big model’s quality at a fraction of the cost.
Common Mistakes I’ve Seen (and Made)
Mistake 1: Using Fine-Tuning When You Need RAG
I’ve seen teams spend weeks fine-tuning a model on their company wiki — only to realise the wiki changes every week. Every update meant retraining. They should have used RAG from day one.
Rule of thumb: If your data changes more than once a month, start with RAG.
Mistake 2: Using RAG When You Need Fine-Tuning
On the flip side, I once built a RAG system for a client who wanted their AI to write in a very specific brand voice. The retrieved context helped with facts, but the tone was always off. Fine-tuning on 500 examples of their brand writing fixed it instantly.
Rule of thumb: If your problem is about how the model responds (style, format, tone), fine-tuning is the answer.
Mistake 3: Bad Chunking Strategy in RAG
This is the most common RAG failure. If you split documents at arbitrary character limits, you’ll break sentences, lose context, and get terrible retrieval quality. Smart chunking (by paragraphs, sections, or semantic boundaries) makes an enormous difference.
Mistake 4: Not Evaluating Retrieval Quality
Most people evaluate the final LLM output but never check whether the retriever is actually finding the right documents. If retrieval is broken, no amount of prompt engineering will fix it. Always measure retrieval precision and recall separately.
Mistake 5: Over-Fine-Tuning
Training for too many epochs on a small dataset leads to overfitting. The model becomes great at parroting your training examples but terrible at everything else. Start with 2-3 epochs and evaluate rigorously.
My Personal Decision Process
When a new AI project lands on my desk, here’s exactly how I decide:
Step 1: What’s the core problem?
- Knowledge access → RAG
- Behaviour change → Fine-tuning
- Both → Hybrid
Step 2: How often does the data change?
- Daily/weekly → RAG (definitely)
- Monthly → RAG or hybrid
- Rarely → Fine-tuning is an option
Step 3: What’s the budget?
- Under $50/month → RAG with a hosted LLM
- $50-500/month → RAG or fine-tuning
- $500+/month → Hybrid, or fine-tuned + RAG
Step 4: What’s the timeline?
- Need it this week → RAG
- Can invest 2-4 weeks → Fine-tuning
- Long-term product → Hybrid architecture
Step 5: How critical is accuracy?
- Must cite sources → RAG
- Must be consistent → Fine-tuning
- Both → Hybrid
For my personal projects, I almost always start with RAG. It’s faster to prototype, cheaper to run, and easier to iterate. Fine-tuning comes later when I’ve validated the use case and have enough data.
Frequently Asked Questions
Is RAG better than fine-tuning?
Neither is universally better. RAG excels at knowledge-heavy applications with frequently changing data. Fine-tuning excels at changing model behaviour, tone, and domain reasoning. For many production systems, combining both gives the best results.
Can I use RAG and fine-tuning together?
Yes, and it’s increasingly common. Fine-tune for behaviour and style, use RAG for dynamic knowledge. The fine-tuned model becomes better at interpreting and using the retrieved context.
How much data do I need for fine-tuning?
OpenAI recommends a minimum of 50 examples, but 200-1,000 high-quality instruction-response pairs is the sweet spot for most use cases. Quality matters far more than quantity.
How much data do I need for RAG?
RAG works with any amount of data — from a single document to millions. The key is proper chunking and embedding quality, not raw volume.
Is fine-tuning worth it for small projects?
Usually not. For small projects, RAG + good prompt engineering gets you 80-90% of the way. Fine-tuning makes sense when you’re at scale or need very specific model behaviour.
What vector database should I use for RAG?
For small projects: a JSON file or SQLite works fine (it’s what I use on this site). For production: Pinecone, Qdrant, Weaviate, or pgvector (PostgreSQL extension) are all solid choices. Pick based on your existing infrastructure.
Does RAG work with open-source models?
Absolutely. RAG is model-agnostic. You can use it with LLaMA, Mistral, Qwen, Phi, or any model that accepts a system/context prompt. I’ve tested RAG with Ollama locally and it works great.
Will fine-tuning make my model hallucinate less?
Not necessarily. Fine-tuning can actually increase hallucinations if the model learns to be confidently wrong from noisy training data. RAG is generally better for reducing hallucinations because it grounds responses in retrieved facts.
Final Thoughts
The RAG vs fine-tuning debate is really about understanding your problem deeply enough to choose the right tool. After building with both extensively, here’s my honest summary:
Start with RAG. It’s faster to build, cheaper to run, and easier to debug. For most applications — especially if you’re dealing with knowledge that changes — RAG is the pragmatic choice.
Add fine-tuning when you need it. When you’ve validated your use case and need specific behaviour, consistent output formats, or domain expertise baked into the model, fine-tuning is worth the investment.
Don’t be afraid of the hybrid approach. The best AI products I’ve built combine both. Fine-tune for behaviour, RAG for knowledge. It’s more complex, but the quality difference is significant.
And if you’re just getting started? Build a simple RAG system. Even a JSON file with embeddings and cosine similarity will get you surprisingly far. I know because that’s exactly how the AI on this website works.